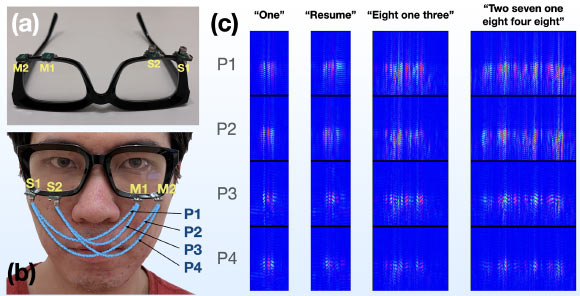
EchoSpeech, developed by Cornell University researchers, uses speakers and microphones mounted on a glass-frame and emits inaudible sound waves towards the skin. By analyzing echoes from multiple paths, EchoSpeech captures subtle skin deformations caused by silent utterances and uses them to infer silent speech.
“For people who cannot vocalize sound, this silent speech technology could be an excellent input for a voice synthesizer. It could give patients their voices back,” said Ruidong Zhang, a doctoral student at Cornell University.
In its present form, EchoSpeech could be used to communicate with others via smartphone in places where speech is inconvenient or inappropriate, like a noisy restaurant or quiet library.
The silent speech interface can also be paired with a stylus and used with design software like CAD, all but eliminating the need for a keyboard and a mouse.
Outfitted with a pair of microphones and speakers smaller than pencil erasers, the EchoSpeech glasses become a wearable AI-powered sonar system, sending and receiving soundwaves across the face and sensing mouth movements.
A deep learning algorithm then analyzes these echo profiles in real time, with about 95% accuracy.
“We’re moving sonar onto the body,” said Dr. Cheng Zhang, also from Cornell University.
“We’re very excited about this system, because it really pushes the field forward on performance and privacy.”
“It’s small, low-power and privacy-sensitive, which are all important features for deploying new, wearable technologies in the real world.”
“Most technology in silent-speech recognition is limited to a select set of predetermined commands and requires the user to face or wear a camera, which is neither practical nor feasible.”
“There also are major privacy concerns involving wearable cameras — for both the user and those with whom the user interacts.”
Acoustic-sensing technology like…
Read the full article here




{kind=link}